
Artificial Intelligence models do not improve simply because more data is available. Their performance depends on the quality, consistency, and accuracy of the training data used in machine learning systems.
This is where data annotation platforms play a critical role, helping organizations create high-quality datasets for AI training.
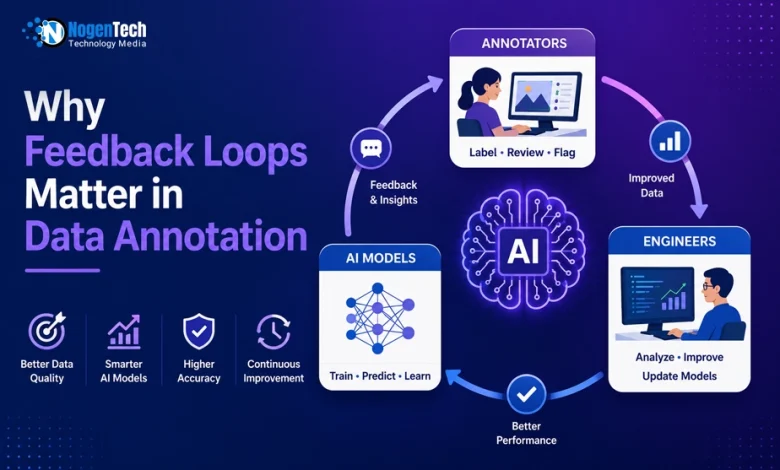
As data evolves and models encounter new scenarios, annotation workflows must adapt through feedback loops that connect:
- Data Annotators
- Engineers
- AI models
These continuous feedback cycles help improve data quality, reduce labeling errors, and strengthen model performance over time.
Moving forward, I’ll walk you through why feedback loops matter and how they support more accurate, reliable, and scalable AI systems.
What Are Feedback Loops?
A feedback loop in data annotation is a structured process through which information about errors, inconsistencies, and performance outcomes flows back into the annotation workflow to drive continuous improvement.
Rather than treating data labeling as a task with a defined start and end, feedback loops treat it as a living system where every correction, flag, and review becomes an input for making the next round of annotations better.
In practice, this means annotators, engineers, and machine learning models are constantly exchanging signals, each layer informing the others about what is working and what needs to change.
The Growing Importance of Data Annotation
According to Grand View Research, the global data annotation tools market is expected to grow significantly as organizations increase investments in artificial intelligence, computer vision, and machine learning initiatives.
As AI adoption accelerates, maintaining data quality throughout the annotation lifecycle has become a critical factor in model performance and reliability.
Why Feedback Loops Are Essential for AI Training
Feedback loops matter because they create a direct path between human judgment and machine learning outcomes. Instead of treating annotation as a single pass that ends once labels are submitted:
- Feedback loops keep the data pipeline open
- Allowing errors to be caught and corrected
- Used to improve the system that produced them in the first place.
They Create a Direct Line to Model Accuracy
When an annotator flags a mislabeled example or an inconsistent guideline, that correction does not just fix one data point. It becomes a signal that engineers can use to adjust labeling instructions, retrain the model, or refine how edge cases are handled.
Over time, this steady exchange of corrections is what drives model accuracy upward, since the model is consistently learning from cleaner, more representative data rather than from static datasets that never get revisited.
They Catch Errors Before They Compound
A single mislabeled example rarely causes serious harm on its own. The risk comes from patterns. If an annotator misunderstands a guideline, that same mistake can repeat across thousands of similar examples before anyone notices.
Feedback loops shorten the gap between when an error occurs and when it gets caught, so a misunderstanding gets corrected after a handful of examples instead of after an entire dataset has been affected.
They Turn Isolated Corrections Into System-Wide Improvements
Without a feedback mechanism, a correction only helps the specific example it was applied to.
With a feedback loop in place, that same correction can be traced back to its root cause, whether that is an unclear instruction, a missing edge case in the guidelines, or a model that consistently struggles with a certain input type.
This allows one fix to improve every future annotation that touches the same issue, rather than solving the problem one label at a time.
How Feedback Loops Create Better Collaboration Between Humans and AI?
Feedback loops ensure human expertise corrects AI mistakes, creating cleaner data and optimized models through continuous collaborative refinement.
Human expertise remains a critical part of modern AI development. Annotators review datasets, identify edge cases, and correct labeling mistakes that automated systems may overlook. Those corrections provide valuable signals that help engineers refine datasets and retrain models more effectively.
This collaborative process creates several benefits:
- Cleaner training datasets
- More reliable predictions
- Faster identification of data quality issues
- Better handling of unusual cases
- Improved AI performance over time
Rather than replacing human involvement, AI systems often become more effective when human feedback remains part of the workflow.
Why is it Necessary for Organizations to Move Beyond One-Time Data Annotation Projects?
It is necessary because static datasets degrade as real-world behaviors change; continuous loops update labels, catch edge cases, and maintain model reliability.
Many organizations treat annotation as a task completed once data is labeled. However, real-world environments constantly change.
New user behaviors, evolving business requirements, and changing data patterns can affect how models perform after deployment. As a result, annotation workflows should evolve alongside the systems they support.
Continuous feedback allows teams to:
- Update outdated labels
- Address newly discovered edge cases
- Improve training datasets
- Reduce future retraining costs
- Maintain long-term model reliability
This approach transforms annotation from a static process into an ongoing quality improvement cycle.
What are the Key Elements of an Effective Feedback System?
Effective feedback systems rely on three primary elements: Annotator-to-Engineer, Model-to-Annotator, and Peer-to-Peer / QA.
Annotator-to-Engineer Feedback
Annotators are often the first people to encounter unclear instructions, inconsistent examples, or problematic data samples.
Many platforms now include some of the best visual feedback and markup tools available, allowing annotators to highlight, comment on, or flag specific regions of an image, video frame, or text span directly within the workflow.
Providing direct communication channels allows them to:
- Report edge cases
- Request guideline clarification
- Suggest workflow improvements
- Flag recurring data issues
When feedback reaches engineering teams quickly, problems can be resolved before they affect larger portions of the dataset.
Model-to-Annotator Feedback
Many modern annotation platforms now incorporate AI-assisted workflows.
These systems may provide:
- Suggested labels
- Confidence scores
- Automated classifications
- Error detection alerts
By reviewing model recommendations, annotators can focus their attention on uncertain or complex examples while allowing automation to handle routine cases.
This creates a more efficient human-in-the-loop workflow.
Engineer-to-Model Feedback
Engineers complete the cycle by analyzing annotation outcomes and updating training processes.
This often involves:
- Retraining generative AI models
- Refining labeling guidelines
- Improving dataset quality
- Monitoring performance metrics
One of the most important measurements is the correction rate, which indicates how frequently human reviewers modify machine-generated labels.
Tracking this metric helps teams understand how effectively models are learning from feedback.
Practical Benefits of Feedback-Driven Annotation
Organizations that implement structured feedback systems often experience measurable improvements across multiple areas.
Higher Data Quality
Regular reviews help ensure labeling consistency and reduce annotation drift.
Benefits include:
- Fewer labeling mistakes
- Stronger agreement among annotators
- Better handling of complex examples
- More reliable training datasets
Consistent data quality directly supports stronger AI outcomes.
Faster Model Improvement
Every correction becomes an additional learning opportunity.
As feedback accumulates, machine learning systems gain access to more accurate examples, helping them improve faster and reducing the need for extensive manual intervention.
This creates shorter development cycles and more efficient model updates.
Improved Team Performance
Feedback systems also benefit annotation teams.
When contributors can see how their work improves model outcomes, they tend to remain more engaged and produce higher-quality annotations.
Effective feedback environments often provide:
- Clear communication channels
- Regular quality reviews
- Performance insights
- Visibility into project impact
These practices help maintain consistency while supporting long-term workforce retention.
What are the Metrics That Matter in Feedback-Driven Annotation?
Organizations should measure feedback effectiveness using objective indicators. Common metrics include:
- Annotation accuracy
- Reviewer agreement scores
- Dataset consistency
- Model performance improvements
- Retraining frequency
- Correction rate
Monitoring these indicators provides a clearer understanding of how annotation quality influences AI development outcomes.
What is the Future of Human-in-the-Loop AI?
As AI adoption expands across industries, human oversight remains essential because feedback-driven systems ensure models continuously learn from real-world expertise.
Automation can accelerate labeling workflows, but feedback-driven systems ensure that models continue learning from real-world expertise. The combination of AI assistance and human judgment is becoming a core component of modern machine learning operations.
Organizations investing in scalable annotation workflows increasingly recognize that continuous improvement produces stronger results than one-time labeling efforts.
What People Also Want to Know About Feedback Loops
What is a feedback loop in data annotation?
It’s a process where corrections, errors, and performance signals flow back into the annotation workflow. This helps teams continuously improve labeling quality and model outcomes.
Why do feedback loops improve model accuracy?
They allow models to learn from corrected, higher-quality examples instead of static datasets. Over time, this steady refinement leads to more accurate predictions.
What is correction rate, and why does it matter?
Correction rate measures how often human reviewers change machine-generated labels. It helps teams understand how well a model is learning from feedback.
Can feedback loops help reduce bias in AI models?
Yes, annotators often catch skewed patterns or underrepresented cases that automated checks miss. Feeding these corrections back into the dataset helps reduce bias before it scales.
Is data annotation a one-time process?
No, real-world data and use cases constantly evolve, so annotation needs to evolve too. Feedback loops keep datasets updated and relevant over time.
Final Thoughts: Why Feedback Loops Are Essential for Long-Term AI Success
As AI adoption continues to grow, organizations can no longer treat data annotation as a one-time task. Effective feedback loops help connect annotators, engineers, and AI models, ensuring datasets remain accurate, consistent, and relevant as conditions evolve.
In my view, feedback-driven annotation is one of the most practical ways to improve data quality, reduce labeling errors, and enhance machine learning performance over time.
Organizations that prioritize continuous feedback are better positioned to build more reliable, scalable, and accurate AI systems while reducing the long-term costs of model maintenance and retraining.



