With digitization accelerating, critical business information now resides dispersed across the web – from social media profiles to review sites listing customer pain points. Web scraping solutions allow aggregating this unstructured data at scale to generate qualified B2B sales leads, conduct market research, and optimize marketing ROI. In this guide, we will discuss web scraping for lead generation.
The Core Concept
Web scraping uses automated bots to systematically trawl through websites, extracting publicly listed data points into structured databases. Instead of manual copying-pasting, specialist software tools and proxy provider servers programmatically harvest data at speeds and scales untenable for humans. Scraped datasets power everything from contact discovery to personalized outreach, driving revenue growth.
Technical Web Scraping Techniques Targeting Diverse Modern Site Architectures
Modern, robust web scraping solutions rely on an expanding repertoire of diverse data harvesting techniques innovatively customized and fine-tuned to target the unique layout paradigms, site structures and access constraints characterizing each website architecture subtype, including:
Pervasive Social Media Scraping
Dedicated social media-focused scrapers efficiently extract both personal and professional details scattered across profiles like domains, divisions, seniorities, technological skills, groups, discussion topics, as well as situational life events customers publicly share. This powers identifying relevant contacts open to marketing messages across previously siloed platforms like LinkedIn, Twitter, Facebook, Instagram, etc.
Real-time Product Intelligence Scraping
Specially designed scraping bots empower dynamic tracking prices, inventory levels, ratings and consumer traction metrics around trending niche products on agile e-commerce marketplaces. This enables price adjustment automation based on competitors, dropshipping arbitrage profits from spotting underpriced items before the masses and other financial use cases benefiting from continuous data feeds.
Elusive Niche Deep Web Uncovering
Beyond heavily indexed surface web pages, recursive link analysis scrapers relentlessly uncover hidden corners of niche web spanning fragmented industry forums, expert review sites and specialized databases housing otherwise unavailable lead contact and segment data using crawling logic resembling how human researchers discover new credible sources. Accessing this dark, open web content provides unique competitive intelligence.
Simulated JavaScript Enabled Scraping
Many modern websites rely on heavy client-side JavaScript to render content within the browser rather than simple server-side generated static HTML. Scraping them requires advanced headless browser bot capability simulating dynamic user interaction events like clicks, scrolls, and form-fills to fully expand pages before extracting behind obstructions protecting data.
Multilingual International Market Scraping
Support for non-English language website content extraction using Optical Character Recognition and machine learning-trained language translation models allows international firms to widen their geographical scoping for data harvesting across both emerging and mature global markets. Reduces reliance solely on English-centric data, limiting complete market visibility.
Vertical Specific Scrapers
Rather than generic extraction, purpose-built scraping solutions finely tuned for targeted data harvesting from niche ecosystem sites relevant to each industry vertical, including contextual media monitoring, clinical trial research platforms in pharma, insurance risk rating sites, hospitality review sites, etc, provide the precision needed by domain experts while benefiting from custom tooling productivity.
Lead Generation Using Web Scraped Data
The power of web scraping comes from leveraging extracted data for critical business applications:
Contact Discovery
Compiling decision maker contact details from scraped company sites and linked social/forum accounts enables targeted outbound pitches bypassing manual lead hunting.
Enrichment
Augmenting existing CRM records with additional organizational hierarchies, technologies used and trigger events scrapers uncover helps personalize engagement.
List Building
Aggregating industry-specific decision maker contact lists around target use cases, technographics, firmographics etc facilitates precise multi-channel nurturing campaigns.
News Monitoring
Tracking mentions of company, product, brand names across news sites and social media with scrapers captures real-time PR visibility, sentiment, and crisis monitoring analytics.
Recruitment
Discovering and sourcing passive but open talent based on skills, experience and other indicators scraped from sites like LinkedIn and Github aids smoother recruitment.
The above examples demonstrate generating tangible ROI from web scraping.
Best Practices for Scraping Success
To maximize outcomes from web data extraction, you need to adopt some of the best practices. In this section, we have compiled a list of such practices that will assist you in getting the most out of scraping success.
Clear Focus
Audit and clearly define essential data needs rather than unfocused mass scraping. By doing so, you will be able to implement web scraping more efficiently and accurately.
Scraper Design
Account for target site structures, tech stacks and data protection controls during scraper design planning to handle intricacies.
Headless Browser Scraping
Employ headless browser scraping, proxies and human-like crawl patterns to minimize getting blocked.
Benchmarks
Develop rigorous throughput benchmarks and progress indicators to calibrate large scale scrape jobs.
Pilot Extractions
Perform initial pilot extractions on sampling of pages to refine scraping rules before deploying at scale.
Cloud Computing
Utilize cloud computing resources for running large scrapers in parallel across multiple threads and IP addresses facilitating faster completion.
Monitoring
Closely monitor scraper performance metrics during active harvesting to troubleshoot failures through logs in real-time.
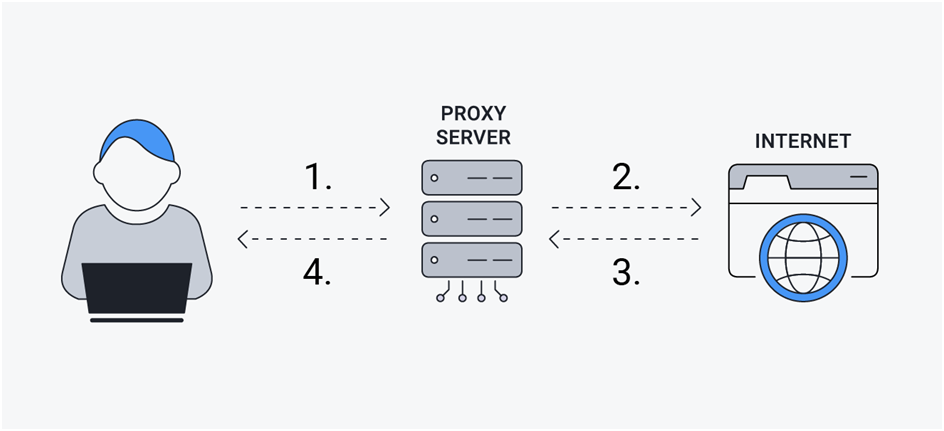
Proxy IP Pools
Continuously expand and iterate proxy IP pools to keep refreshing site access. This approach will assist you in effective web scraping process for better outcomes.
Mask Data
Mask data ingestion origin using offshore proxy IPs, avoiding target domain blocklists.
Terms and Conditions
Strictly comply with sites terms to ensure web scraping stays on the right side of ethics and emerging regulations globally.
Final Verdict
Web scraping is the process of extracting data from a certain website for better outcomes in the long run. As websites continue to increase exponentially in complexity, successfully extracting maximum data relies on innovating sophisticated scraping techniques optimized per each platform while complying ethically with reasonable usage terms. With strategic planning, savvy implementation and responsible oversight, web data extraction drives tremendous bottom-line business impact across industries in the data age. Scout the web and transform engagements. Blending automation with expert refinement provides outsized business impact from web data harvesting.